



Par le Dr Alex Beasley - Ziath Ltd
 Le Dr Alex Beaseley, ingénieur principal en conception électrique, examine les applications actuelles de l’intelligence artificielle à des problèmes réels dans le domaine des instruments scientifiques. Il montre comment une approche par réseau neuronal peut être déployée, pour analyser des images du monde réel et déterminer des caractéristiques clés à partir des données, avec beaucoup plus de précision et beaucoup plus rapidement qu’avec les techniques de détection traditionnelles.
Le Dr Alex Beaseley, ingénieur principal en conception électrique, examine les applications actuelles de l’intelligence artificielle à des problèmes réels dans le domaine des instruments scientifiques. Il montre comment une approche par réseau neuronal peut être déployée, pour analyser des images du monde réel et déterminer des caractéristiques clés à partir des données, avec beaucoup plus de précision et beaucoup plus rapidement qu’avec les techniques de détection traditionnelles.
Depuis ces dernières années, la communauté scientifique envisage de plus en plus l’intelligence artificielle (IA) comme un outil d’avenir pouvant apporter des avancées majeures sur les opérations et mesures effectuées par les instruments. Mais qu’entend-on précisément par IA ?
Commençons par proposer quelques définitions sur certains termes que vous aurez probablement déjà rencontrés : l’apprentissage automatique (machine learning) est le processus qui permet de créer une intelligence artificielle (IA). L’apprentissage automatique peut être appliqué par le biais de différents mécanismes, notamment la « logique floue » (fuzzy logic), l’« analyse discriminante » (discriminant analysis) et les « réseaux neuronaux » (neural networks). En raison de leur capacité à traiter des problèmes à forte intensité de calcul, les réseaux neuronaux constituent la base de la plupart des solutions IA commercialement viables et pouvant être appliquées aux types de problèmes que les instruments scientifiques tentent de résoudre.
La limite de l’implémentation d’un réseau neuronal est simplement le nombre de « nœuds », ou connexions possibles, du processeur utilisé. Le nombre de nœuds dans le cerveau humain est supérieur de plusieurs ordres de grandeur à celui que peuvent atteindre les processeurs les plus puissants. Le fameux « point de singularité » dont on entend tant parler et à partir duquel une conscience humaine pourrait être téléchargée in silico, ne relève pour le moment que de la science-fiction. Pour autant, dans le monde réel, les réseaux neuronaux ont effectivement un rôle important à jouer.
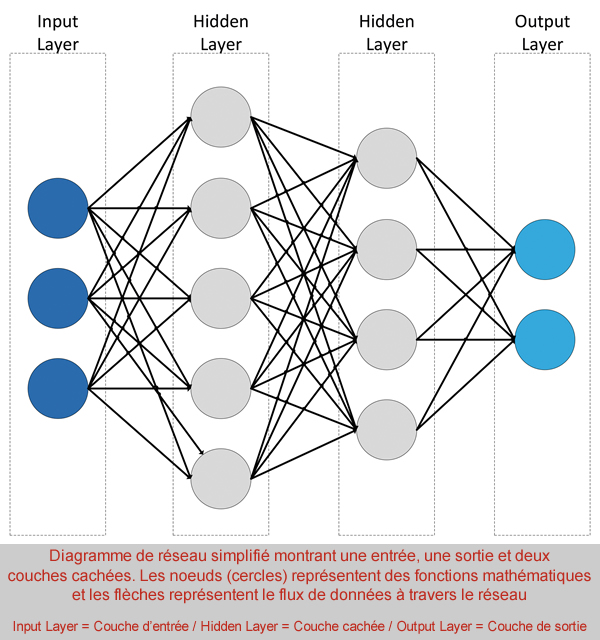
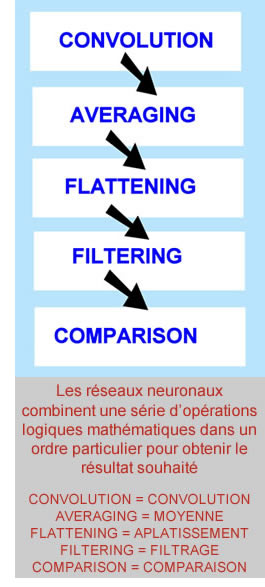
Pour appliquer avec succès une solution IA à un problème donné, nous devons commencer par caractériser le problème. Il s’agit généralement d’une solution mathématique à un problème spécifique d’analyse des données, tel un algorithme de lissage ou l’identification des tendances des données. Lors de la conception d’un réseau neuronal, le réseau est constitué d’un certain nombre de « couches », où chaque couche représente une opération mathématique distincte. La combinaison de ces fonctions mathématiques sur un flux de données permet d’extraire les caractéristiques de ces dernières. Cela pourra directement une réponse utile au problème posé, ou constituer une étape intermédiaire qui permettra d’effectuer un traitement ultérieur. Ainsi par exemple, un réseau peut établir deux ou trois façons différentes de calculer la moyenne d’un ensemble de données. Les résultats pourront ensuite être transmis à un comparateur qui sélectionnera la réponse la mieux adaptée parmi les trois qui lui sont présentées, en fonction des pourcentages de probabilité qu’elle soit correcte.
Lors de la création du réseau neuronal, celui-ci se comporte initialement comme une « boîte noire », c’est-à-dire qu’il n’y a pas d’interconnexions nodales prédéterminées au sein du réseau ; aucun nœud ou chemin possible à travers le réseau n’a été associé à une pondération ou un biais particulier. Cela constitue le point de départ de l’IA.
 La détermination de l’ensemble de données à utiliser est essentielle à la caractérisation du problème qui sera résolu grâce à l’IA. Dans notre cas, il s’agit d’un fichier image .PNG, mais n’importe quel jeu de données peut servir de point de départ. L’IA est particulièrement utile pour l’analyse d’images et a déjà trouvé une application en histocytologie pour la détermination des types de cellules du cancer du col de l’utérus dans les essais de frottis. L’algorithme IA s’est révélé d’une précision de presque 100% dans l’identification de cellules tumorales potentielles. Il est aussi performant le vendredi à 17 heures qu’un lundi à 9 heures, et ne connaît pas la fatigue, contrairement aux techniciens humains qui effectuent actuellement ces tests.
La détermination de l’ensemble de données à utiliser est essentielle à la caractérisation du problème qui sera résolu grâce à l’IA. Dans notre cas, il s’agit d’un fichier image .PNG, mais n’importe quel jeu de données peut servir de point de départ. L’IA est particulièrement utile pour l’analyse d’images et a déjà trouvé une application en histocytologie pour la détermination des types de cellules du cancer du col de l’utérus dans les essais de frottis. L’algorithme IA s’est révélé d’une précision de presque 100% dans l’identification de cellules tumorales potentielles. Il est aussi performant le vendredi à 17 heures qu’un lundi à 9 heures, et ne connaît pas la fatigue, contrairement aux techniciens humains qui effectuent actuellement ces tests.
La couche d’entrée du réseau neuronal est définie par la taille du flux de données d’entrée. Dans notre cas, il s’agit d’une image 8 bits de 50 x 50 pixels où chaque pixel a une valeur possible comprise entre 0 et 225. Chaque couche par laquelle transitent ces données, en séquence, constitue un argument mathématique distinct. La combinaison des fonctions mathématiques permet d’obtenir une fonction globale plus importante, telle que la classification des images.
Le rôle du réseau de classification est de décider, ou de classer, le contenu de l’image en fonction d’un ensemble de paramètres prédéterminés. Par exemple : la sortie est-elle égale à zéro, à un ou supérieure à un ? Il peut également s’agir d’une simple réponse oui/non ou du fait qu’un code-barres soit présent ou non. Dans notre cas, le réseau de classification produit deux réponses : la probabilité que l’image contienne un code-barres et la probabilité que l’image ne contienne pas de code-barres. La sortie est envoyée à un comparateur qui examine le résultat et donne la réponse à la question : notre image contient-elle un code-barres ? Si le réseau fait une erreur, il doit être « ré-entraîné ».
Dans un réseau sophistiqué, des techniques telles que la « fonction d’Adam » peuvent être utilisées pour explorer une zone de « l’espace des solutions », c’est-à-dire, en termes graphiques, la surface délimitée par le lieu géométrique de toutes les solutions valides possibles aux arguments mathématiques.
En pratique, le réseau est « entraîné » en lui présentant un grand nombre d’exemples connus, généralement plusieurs milliers. La nature du contrôle d’un réseau neuronal permet au réseau d’ajuster les pondérations et biais de chaque nœud afin de faire « croître » le réseau dans une direction qui ressemble davantage aux solutions autorisées. Dans notre cas, nous présentons au réseau des milliers de codes-barres différents, certains de bonne qualité, certains mal imprimés et d’autres carrément inutilisables ! Notre réseau s’ajuste jusqu’à ce que, finalement, il soit capable de faire la différence entre un bon code-barres et un code-barres mal imprimé. Avec un apprentissage complémentaire, il pourra aussi déterminer si aucun code-barres n’est présent. Tout cela peut sembler simple et évident mais, en pratique, de nombreux facteurs intervenant dans le laboratoire, par exemple l’éclairage au plafond, la proximité des fenêtres, l’heure de la journée et les réflexions des puits adjacents remplis, peuvent amener l’imageur à percevoir un code-barres alors qu’il n’y en a pas.
Une fois entraîné, le réseau doit être vérifié. Un jeu de données de vérification, représentant environ 20% de la taille de l’ensemble d’apprentissage, contenant de nouvelles images pertinentes, sera utilisé pour évaluer les performances du réseau.
En pratique, les réseaux tendent à être « surentraînés », de sorte qu’ils sont exceptionnels dans le traitement de l’ensemble de données d’apprentissage, mais échoueront lamentablement lorsqu’on leur présente de nouvelles données. Pour atténuer ce problème du « surentraînement », un certain nombre de techniques peuvent être utilisées : on pourra, par exemple, augmenter les données de formation et forcer le réseau partiellement formé à perdre ses valeurs actuelles de pondérations et de biais (ce que l’on appelle un dropout ou « régularisation par abandon »). L’augmentation des données permet d’effectuer des transformations, des rotations et d’autres opérations de prétraitement des images sur notre ensemble de formation. L’augmentation des données permet de veiller à ce que la variété des images utilisées par le réseau pour l’entraînement soit accrue, limitant ainsi la tendance à créer un réseau « surentraîné ». L’abandon (dropout) est un autre processus qui permet de réduire le « sur-entraînement » : un pourcentage des pondérations/biais utilisés dans l’apprentissage est supprimé de manière aléatoire entre les époques d’apprentissage. Le réseau neuronal doit alors réapprendre les pondérations lorsqu’une autre itération des données d’apprentissage lui est présentée. En évitant ainsi le « sur-entraînement », lorsqu’on présente au réseau de toutes nouvelles données, par exemple celles de l’ensemble de vérification, il parvient à obtenir un score aussi élevé que celui de l’ensemble d’apprentissage. Une fois qu’un réseau est en mesure d’obtenir un score élevé sur des données entièrement nouvelles, on considère qu’il est prêt à être déployé.
Un certain nombre de cadres d’apprentissage peuvent être utilisées pour le développement et la formation de réseaux neuronaux, notamment Tensorflow, PyTorch, Torch et Keras. Ces cadres utilisent des langages de programmation courants tels que Python. Les cadres d’apprentissage offrent une plateforme open source de bout en bout pour l’apprentissage automatique, avec une suite d’outils et de bibliothèques qui permettent aux développeurs de créer et déployer aisément des applications alimentées par le machine learning, par exemple l’analyse d’images scientifiques.
Ziath a choisi de mettre en œuvre un puissant réseau neuronal au sein de son dernier logiciel de contrôle, DP5, pour ses lecteurs de tubes à code-barres 2D basés sur une caméra CMOS. Cette nouvelle fonctionnalité IA sous-tend la détermination du puits vide, ou tube manquant, du logiciel Ziath en utilisant précisément la méthode décrite ci-dessus. Cela permet une détermination de la présence ou de l’absence d’un tube à chaque puits.
L’équipe R&D de Ziath s’attache désormais à transférer le réseau neuronal sur un FPGA, c’est-à-dire une matrice de portes programmables. Le principe d’un tel dispositif consiste à combiner des milliards de transistors en une plateforme, à partir de laquelle des architectures personnalisées pourront être créées pour résoudre le problème spécifique de l’utilisateur. Les FPGA présentent un certain nombre d’avantages par rapport à d’autres technologies de traitement : elles offrent une plateforme flexible capable d’actualiser sa configuration sur le terrain ; leurs performances sont très élevées par rapport aux autres processeurs et elles permettent un développement rapide par rapport au silicium personnalisé. La traduction du réseau neuronal selon cette méthode déterminera l’architecture, la taille, la capacité et le coût de la FPGA.
Pour autant, le modeste dispositif destiné à l’application de Ziath peut fonctionner beaucoup plus rapidement que le PC embarqué utilisé pour la prendre en charge, de sorte qu’un réseau encore plus grand et plus puissant pourrait être intégré à l’avenir, si nécessaire. Cette FPGA effectue des giga-opérations par seconde à une vitesse d’horloge de 125 MHz, ce qui lui permet d’analyser un rack au format SBS de 96 positions en un peu moins de 8 millisecondes. Une plus grande FPGA permettrait un traitement encore plus rapide, mais les coûts augmentent proportionnellement et le système est limité par d’autres goulots d’étranglement, tels que les transferts de données entre les différents dispositifs.
Comme nous l’avons déjà indiqué, l’apprentissage automatique permet de traiter très efficacement certains problèmes d’analyse d’images (ce qu’on appelle la vision artificielle). Il peut identifier certaines caractéristiques déterminantes à très haute résolution, que l’œil humain peinerait à résoudre. Par ailleurs, la déconvolution des données superposées, comme les spectres ou les chromatogrammes, se prête aussi à une solution IA. En laboratoire, l’IA pourrait prendre en charge n’importe quel grand ensemble de données nécessitant une reconnaissance des formes. Dans d’autres domaines, des méthodes sont en cours de développement pour réduire la quantité de données d’apprentissage nécessaires pour conditionner un réseau neuronal, ce qui rendrait leur application plus facile et plus rapide.
En laboratoire, l’IA porte la promesse d’un traitement des données plus rapide, plus sensible et moins cher qu’avec les techniques actuelles.
Contact :
Ziath Ltd
https://ziath.com - info@ziath.com
Partager cet article :
![]()
![]()
![]()
![]()
![]()